GPT-5.2居然反超谷歌Gemini 3 Pro!北大数院学友中枢孝顺
梦晨 发自 凹非寺
量子位 | 公众号 QbitAI红色警报拉响,OpenAI是真急了:
30天,GPT-5.2系列紧接着GPT-5.1而来,此次还特意强化了打工智商。
这是GPT-5.1 Thinking和GPT-5.2 Thinking作念东说念主力资源表格的对比:
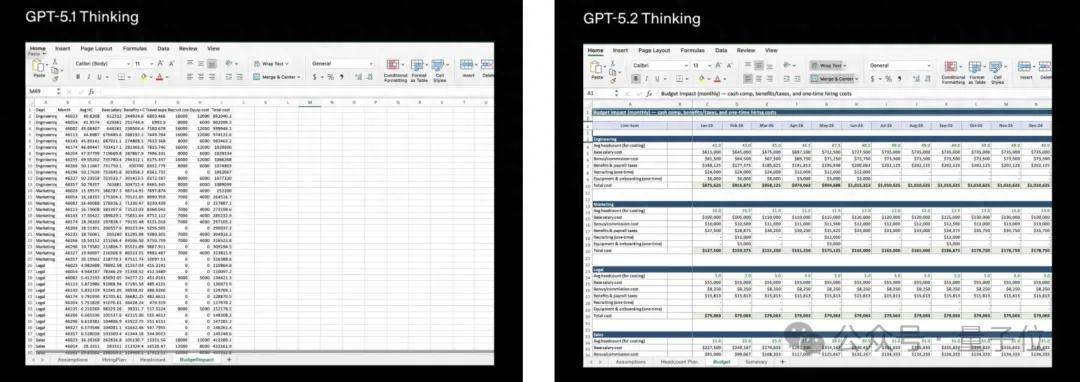
天然版块号只加了0.1,然而在多个实用限制都更强了:作念表格、作念PPT、写代码、默契长文档、调用用具、处理复杂多挨次技俩……
视觉默契智商也大幅升迁,GPT-5.2能准确象征出更多主板上的元件。

这是GPT-5.2作念的网页版海潮模拟器:
若是你遭受航班延误、又错过出动、需要当地过夜以及需要罕见医疗座位,听起来就很头疼。
但GPT-5.2安排好了一切:再行订机票、安排罕见座位和抵偿。
ARC-AGI也在第一技能发布了测试放手。
一年前的o3 (High) 在ARC-AGI-1测试中得分88%,平均每项任务资本为4500好意思元。
今天的GPT-5.2 Pro (X-High) ,最新SOTA得分为90.5%,平均任务资本仅为11.64好意思元,在一年内效能提高了约390倍。
同期向上了谷歌Gemini 3 Pro的对应版块(绿色点),也算扳回一局。
拆解GPT-5.2各项智商高经济价值任务
在GDPval测试中,涵盖好意思国GDP前九大产业中的44个处事限制,完成东说念主类需要4-8小时才略完成的任务。
在东说念主类评委打分下,GPT-5.2 Thinking与东说念主类众人比较有71%的胜率,GPT-5.2 Pro还能更高一些。
况兼速率是东说念主类众人的11倍以上,资本不到东说念主类众人的1%。
在投行分析师的电子表格建模任务上,GPT-5.2 Thinking平均每项任务得分比较GPT-5.1升迁了9.3%,从59.1%高潮到68.4%。这些任务包括为钞票500强公司搭建三表联动模子、构建杠杆收购模子等。
领导:您是别称投资银行分析师,刚刚接到一项任务,需要完成一份瀑布式分析,以了解首创东说念主及现存投资者的总共权和报酬情况。您的客户是一家正在酌量 C 轮融资的初创公司。
请查收附件中的模板,您需要对其进行修改。我在 G 列中添加了必要的假定。C 列的称呼在粗糙股部分重叠出现,以便于索引。假定包括退出时的股权、系列投资金额、基金总共权、认股权证、清理优先权、调整价钱、粗糙股稀释后股份数和行权价钱。假定种子轮、A 轮和 B 轮均为同等权柄的非参与性优先股(即,这些轮次的投资者享有同恭候遇;对借款东说念主的资产领有同等的索偿权)
在审查一份非常优秀的后果时,一位GDPval评委暗示:
在输出质地上令东说念主欢乐且显耀的飞跃……[它]看起来像是由一家专科公司的职工完成的,两份请托后果的布局联想和建议都出东说念办法想地出色,尽管其中一份仍存在一些小造作需要修订。
要在ChatGPT中使用新的作念表格和PPT智商,需要充值Plus、Pro、Business或 Enterprise套餐,遴荐GPT-5.2 Thinking或Pro版块 。生成复杂的内容可能需要几分钟技能。
代码智商GPT-5.2代码智商一样刷新记载,在SWE-bench Verified上,得分达到80%。
在SWE-Bench Pro这个更难的软件工程评测上,GPT-5.2 Thinking拿下55.6%的新高。
这个评测不啻测Python,还包括JavaScript、TypeScript和Go,更面对信得过工业场景。
早期测试者非常提到,GPT-5.2在前端修复和复杂UI责任上明显更强,尤其是触及3D元素的场景。
长凹凸文
长文档处理是此次升级的重头戏。
在OpenAI平正的大海捞针MRCRv2评测中,GPT-5.2 Thinking成为首个在256k 凹凸文长的4针版(4-needle variant)上达到接近100%准确率的模子。
不外8针版性能依然会随凹凸文长度明显下跌。
关于需要卓绝最大凹凸文窗口进行想考的任务,GPT-5.2 Thinking兼容破坏回答格局,粗略处理更多用具密集型、长技能初始的责任流。
视觉默契视觉智商的升迁一样显耀。
在科学论文图表默契上,GPT-5.2 Thinking的造作率大致镌汰了一半。
更要津的是,它对图像中元素的空间位置有了更强的把捏。
在高离别率图形面屏幕截图推理测试中,阿谀Python用具得分达到86.3%。
若是禁用Python用具得分会低好多,OpenAI建议在这么的视觉任务中通通启用用具。
用具调用用具调用智商一样达到新高度,在Tau2-bench Telecom多轮交互电话客服场景评测上,GPT-5.2 Thinking得到98.7%的获利。
Tau2-bench Retail零卖场景也达到82%。
这些获利意味着更强大的端到端责任经由,举例处分客户维持案例、从多个系统中提真金不怕火数据、初始分析以及生成最终输出,且各挨次之间的故障更少。
科学智商OpenAI一直但愿AI能加快科学接洽,此次他们肯定GPT-5.2 Pro和GPT-5.2 Thinking是当今寰宇上最相宜扶持科学家的模子。
在GPQA Diamond接洽生水平的问答评测上,GPT-5.2 Pro拿下93.2%,GPT-5.2 Thinking紧随后来达到92.4%。
在众人级数学评测FrontierMath(Tier 1-3)上,GPT-5.2 Thinking以40.3%的解题率创下新记载。
官方还透露了一个实践案例:
接洽东说念主员使用GPT-5.2 Pro探索了统计学习表面中的一个绽放问题,在一个窄小、明确的设定下,模子提议了一个阐扬,随后被作家考据并经过同业评审。
事实准确性方面,GPT-5.2 Thinking的幻觉问题比较GPT-5.1从8.8%减少到6.2%。
不外OpenAI也领导模子仍不完好,要津内容依然需要东说念主工复核。
One More Thing
自从Meta荒诞挖东说念主以来,OpenAI都很少在接洽推崇著述后头附上孝顺者列表了,获胜和谐签字OpenAI了事。
不外从修复者相互道贺的推文中,依然不错挖出GPT-5.2的几位中枢团队成员:多为2024年之后加入OpenAI的新边幅,况兼多是数学专科树立。
Yu Bai:北大数院学友、斯坦福统计学博士,2024年5月加入OpenAI。
Yaodong Yu:UC伯克利博士毕业,2024年9月加入OpenAI。
Yufeng Zhang:本科中科大数学系、西北大学博士、字节前接洽员,2024年底加入OpenAI
梅松:北大数院学友、斯坦福忖度打算与数学工程博士、UC伯克利助理教育,2025年5月暂离学校加入OpenAI。
Ofir Nachum:MIT CS硕士毕业,前谷歌大脑接洽员,2023年加入OpenAI。
每当外界以为OpenAI推崇不足预期的时候,总有新的东说念主才带来新的惊喜。
参考王人集:
[1]https://openai.com/zh-Hans-CN/index/introducing-gpt-5-2/